-
 TSG-QC : Outils d’analyse interactive des données de température et salinité de surface
TSG-QC : Outils d’analyse interactive des données de température et salinité de surface
-
TSG-QC: A tool for interactive quality control of sea surface temperature and salinity
-
Configuration et utilisation de WSL (Windows Subsystem for Linux)
-
MSYS2 : des outils de développement UNIX sous Windows
-
Premiers pas avec le langage GO
Subversion
Publié le mercredi 21 février 2007.Dernière mise à jour : 26/03/2009
Présentation
Subversion est un projet récent de logiciel de gestion de version apparu en 2000 et conçu pour remplacer le vieillissant CVS dont il reprend les concepts et la philosophie tout en corrigeant les défauts de son prédécesseur.
Un tel logiciel est une aide précieuse au développement, et ce, même pour un programmeur isolé, car il permet de travailler efficacement et simplement sur les multiples versions d’un projet sans que l’utilisateur n’ait à se préoccuper de la sauvegarde et de l’archivage des versions successives.
Installation
Deux types d’installations sont possibles, l’une utilisant le protocole WebDav et un serveur Apache, l’autre consistant a utiliser un serveur svnserve au travers du port 3690.
Subversion propose deux architectures pour l’archivage du référentiel sur le serveur : BerkeleyDB ou FSFS. Le lecteur trouvera des informations complémentaires ici pour effectuer son choix.
Récupérer les sources de subversion depuis le site de téléchargement :
http://subversion.tigris.org/project_packages.html
Pour une compilation à partir des sources, il faut récupérer les 2 archives subversion et subversion-deps.
$ cd /usr/local/src
$ wget http://subversion.tigris.org/downloads/subversion-1.4.3.tar.bz2
$ wget http://subversion.tigris.org/downloads/subversion-deps-1.4.3.tar.bz2Avant de ce lancer dans la compilation des sources, il faut au préalable que le module apxs soit installé avec le serveur Apache.
Vérifier avec votre gestionnaire de paquets, yum, par exemple, l’installation du module httpd-devel
$ yum list httpd-devel
Setting up repositories
Reading repository metadata in from local files
Installed Packages
httpd-devel.i386 2.0.52-28.ent.centos4 installedsi ce n’est pas le cas, installer le paquet :
# yum install httpd-develDans le cas d’une distribution plus ancienne, ce qui est le cas de mon serveur de base de données PostgreSQL sous Fedora core 2, il peut être nécessaire d’installer manuellement à partir du CDRom d’autre paquets dont dépend httpd-devel (apr, apr-util par exemple).
Si vous choisissez Berkeley DB pour archiver le référentiel sur votre serveur, il faut préalablement l’installer, version Berkeley DB 4.5 comme suit avant la génération du Makefile :
$ cd /usr/local/src/db-4.5.20
$ cd build_unix
$ ../dist/configure --prefix=/usr/local/db-4.5
$ make
$ su
# make installDécompresser les archives de subversion
$ tar jxvf subversion-1.4.3.tar.bz2
$ tar jxvf subversion-deps-1.4.3.tar.bz2puis générer le makfile avec la commande configure suivante :
./configure --prefix=/usr/local/svn --with-apxs=/usr/sbin/apxs --with-ssl --with-berkeley-db=/usr/local/db-4.5Vérifier attentivement le résultat (assez bavard). Si tout semble correct, lancer la compilation avec make
$ make
# make installConfiguration du serveur
Tableau comparatif des méthodes d’accès au serveur subversion :
svn.serverconfig.overview
Webdav
Nous aurons principalement 2 possibilités pour créer un référentiel subversion, la première consistant à créer une nouvelle arborescence vierge avec la commande snvcreate, la deuxième consistant à importer un projet existant sous CVS.
Pour créer l’arborescence d’un nouveau projet sous un répertoire, par exemple /export/home/svn, suivre la procédure suivante :
Donner les droits au serveurs apache sur le/les répertoires :
$ mkdir /export/home/svn
$ svnadmin create /export/home/svn/projet
$ chown -R nobody:nogroup /export/home/svn/projetLe propriétaire des droits sur le serveur apache peut différer suivant l’installation et la distribution utilisée (apache, nobody, etc...)
Rajouter les lignes suivantes à la fin du fichier de configuration d’apache :
<Location /test>
DAV svn
SVNParentPath /export/home/svn
</Location>puis redémarrer le serveur apache :
# /sbin/service httpd restartPour plus de détail, se reporter à la documentation en ligne. L’utilisation de la directive SVNParentPath, permet de gérer l’ensemble des projets depuis un répertoire racine. Si les projets se trouvent sur plusieurs systèmes de fichiers, on utilisera la directive SVNPath associé à de multiples balises Location.
Contrôle d’accès
Dans le paragraphe précédent, le contrôle d’accès au niveau utilisateur n’a pas été mis en place. Il est bien évidemment nécessaire du contrôler l’accès aux fichiers ou l’on pourra dissocier les accès en lecture, dit anonyme, des accès en écriture, contrôlés par login/passwd.
Subversion autorise un choix très large dans les différentes méthodes d’authentifications décrites en détails dans la documentation officielle.
Svnserve
2 possibilités principales d’utilisation :
- Mode démon
$ svnserve -d -r <path>/<repositories>
$ svn checkout svn://host.domaine.fr/projet1
- Avec inetd ou xinetd : créer un groupe et un utilisateur svn
# groupadd -g <gid> svn
# useradd -c "SVN Owner" -d /<path>/svn -g svn -s /bin/false -u <uid> svn
Modifier éventuellement le fichier /etc/services :
svn 3690/tcp # Subversion
svn 3690/udp # SubversionAjouter la ligne suivante au fichier /etc/inetd.conf :
svn stream tcp nowait svnowner /usr/bin/svnserve svnserve -i -r /<path>/svnPour xinetd, créer le fichier sous /etc/xinetd.d/svn contenant :
service svn
{
port = 3690
socket_type = stream
protocol = tcp
wait = no
user = svn
server = /usr/local/svn/bin/svnserve
server_args = -i -r /<path>/svn
}Le chemin de la directive server dépendra bien évidemment de l’emplacement de votre binaire svnserve choisit lors de l’installation de svn. Cet emplacement peut différer d’une distribution à une autre, de la directive —prefix choisie lors de la génération du makefile, etc...
Redémarrer le serveur :
# /etc/init.d/xinetd restartVérifier les dernières lignes du fichiers /var/log/messages pour vérifier le bon fonctionnement du serveur et la prise en compte des modifications.
Tester l’accès anonyme :
$ cd <quelquepart>
$ svn co svn://<domaine>/<projet>/trunk <projet>/trunkDans le cas ou il est nécessaire de gérer de multiples projets sous subversion, il peut être intéressant et même nécessaire de définir un modérateur par groupe d’intérêt.
Dans ce cas, il sera préférable de n’autoriser que des accès anonyme au travers du serveur webdav, et de mettre en place le serveur svnserve pour les accès en écriture sur le référentiel.
En effet, chaque projet comporte un répertoire conf dans lequel il sera possible de définir une stratégie d’authentification fine par login/passwd, stratégie qu’il sera plus difficile de mettre en place sous webdav, le modérateur devant avoir les droits de modifier le fichier de configuration du serveur apache.
$ ls -1 conf
authz
passwd
svnserve.confLe fichier passwd sera modifié par le modérateur, via un accès ssh par exemple, en accord avec les directives du fichier svnserve.conf :
anon-access = none
auth-access = write
password-db = passwdPour une description détaillée de la configuration du mode svnserve, se référer à la documentation officielle, configuration du serveur.
Il est également possible d’utiliser un tunel ssh pour établir une connexion cryptée lors des échanges avec le serveur. Se référer au paragraphe : Tuneling over ssh.
Migration de CVS vers SVN
Récupérer les sources de cvs2svn sous http://cvs2svn.tigris.org/cvs2svn.html et décompresser l’archive
$ cd /usr/local/src
$ tar zxvf cvs2svn-1.5.1.tar.gz
$ cd cd cvs2svn-1.5.1
# make install
$ cvs2svn --helpIl faut également avoir RCS installé pour que cvs2svn fonctionne correctement.
# rpm -Uvh /mnt/cdrom/Fedora/RPMS/rcs-5.7-24.i386.rpmConversion d’un projet CVS
Récupérer une archive compressée d’un projet sur votre référentiel cvs. La copier et la décompresser sur votre disque.
Il faut avoir les droits en écriture sur le répertoire pour effectuer la conversion.
$ ls
cvs svn tmp
$ cd tmp
$ scp login@nom.domaine.fr:<path>/projet/archive.tar.gz .
$ tar zxvf archive.tar.gz
$ cd svn/tmp
$ cvs2svn -s projet ../../tmp/projet
$ cd ..
$ mv projet ../../svn
$ cd ../..
$ chown -R apache:apache svnImportation d’un nouveau projet
Avant importation d’un projet, il faut créer le dépot sur le serveur avec svnadmin
svn# svnadmin create projet --fs-type bdb
svn# chown -R apache.apache projetIl faut également créer l’arborescence du projet dans un dossier temporaire sur le client avant importation en respectant les conventions utilisées avec svn :
tmp/projet/trunk
tmp/projet/tags
tmp/projet/branches
</codes>
Copier votre codes sous tmp/projet/trunk puis importer le projet avec svn co:
<code>
$ svn import projet http://url/svn/projet --username user --password passwd -m "Import initial de projet"
Adding projet/trunk
Adding projet/trunk/tsg-main
...Se placer ensuite sous la racine de vos copie locales et faire un checkout du projet :
~/svn$ svn co http://url/svn/projet/trunk projet/trunk
A projet/trunk/tsg-main
A projet/trunk/tsg-main/deco_TS_cb.m
...Sauvegarde d’un dépôt
Pour sauvegarder un dépôt ou migrer un dépôt vers une nouvelle URL, utiliser la commande svnadmin dump
$ svn dump <chemin> > <fichier_texte>Voir commande svnadmin dump.
Utilisation
Avec le client svn en ligne de commande (linux, cygwin) :
$ mkdir -p ~/svn/projet
$ cd ~/svn/projet
$ cvs co http://nom.domaine.fr/svn/projet/trunkOn utilisera ensuite les commandes update, commit, delete, remove, rename, log, status, info, blame, etc..., pour travailler et mettre à jour les fichiers de la copie locale.
Pour avoir de l’aide sur la syntaxe des commandes :
$ svn --helpPour obtenir une aide détaillée pour chaque commande, par exemple :
$ svn rename --helpSous Windows, télécharger le logiciel Tortoise, créer sur votre disque un répertoire (c :\svn par exemple) pour votre copie locale du référentiel puis, par un clic droit faire un checkout.
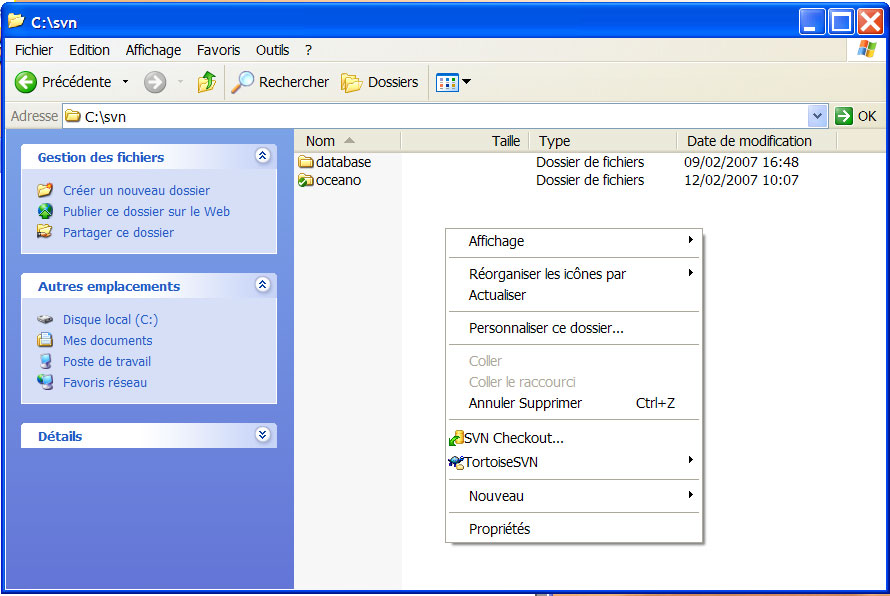
- svn checkout
- clic droit, svn checkout
Ensuite, entrer l’URL du référentiel ainsi que le répertoire local de destination.
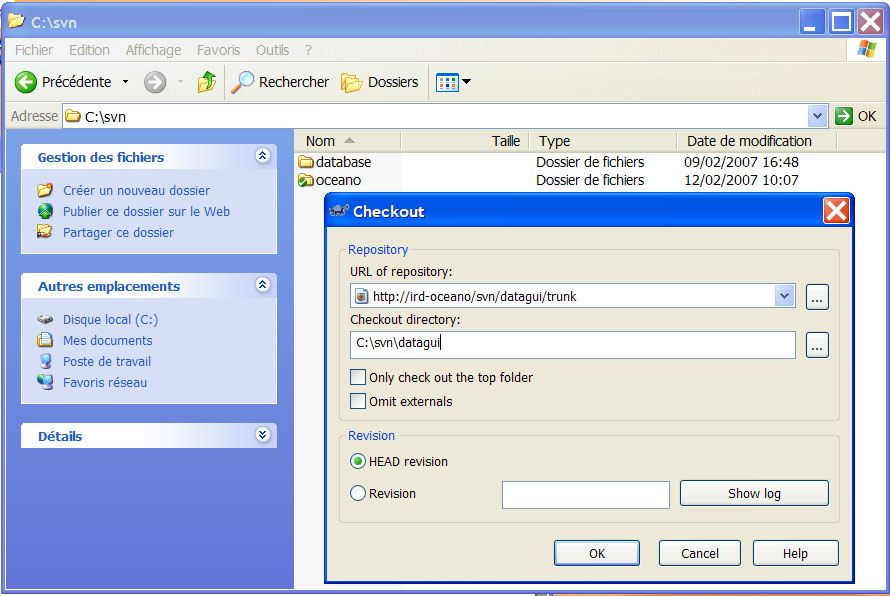
- svn checkout 2
- choit du référentiel et de la copie locale
On peut suivre la récupération des fichiers dans la fenêtre de log
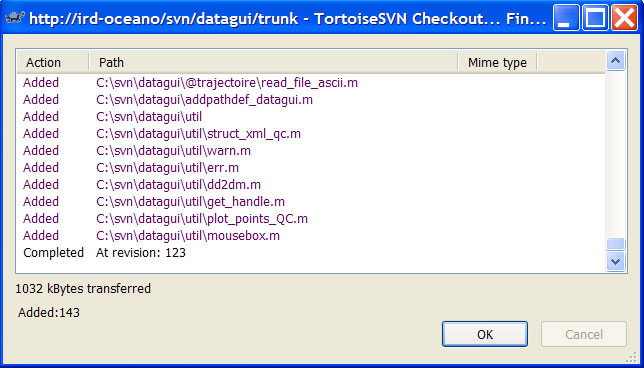
- checkout 3
- checkout en cours de réalisation
On pourra ensuite suivre visuellement les modifications réalisées sur les fichiers de la copie locale par une modification du recouvrement des icônes. Pour plus d’explication, se référer à la documentation PDF sur l’utilisation de Tortoise.
Utilisation avancée
L’objectif de ce document n’étant pas de reprendre la liste des commandes, au demeurant fort bien documentées et expliquées dans le document Version Control with Subversion, je me contenterais ici d’éclaircir quelques points de détails dans l’utilisation de subversion.
checkout
Lorsque l’on récupère une copie locale, il n’est pas toujours nécessaire de récupérer l’intégralité du projet, incluant la branche principale (le tronc de l’arbre de développement), appelé trunk, les branches et les tags.
Contrairement à CVS, sous subversion le "trunk", les branches et les tags sont des répertoires. Il faut savoir que cette organisation n’est qu’une convention de nommage proposée par subversion.
Pour récupérer une copie locale du tronc, il faudra donc lancer la commande suivante :
$ cd svn
$ svn co http://domaine.fr/svn/projet/trunk projetDans cet exemple, nous supposons que nous ne travaillons que sur la branche principale. Si l’on veut pouvoir travailler par la suite sur les branches du projet, le plus simple est de faire ceci :
$ svn co http://domaine.fr/svn/projet/branches projetPour récupérer l’intégralité du projet, incluant le tronc, les branches et les tags :
$ svn co http://domaine.fr/svn/projet projetAttention : Récupérer l’intégralité du projet peut vite devenir très important en terme d’espace disque.
update
$ svn up [-r] [fichier|chemin...]Lorsque l’on a fait un commit, l’ensemble des fichiers du référentiel prennent la numérotation du dernier commit. Pour que la copie locale soit également à jour, il est nécessaire de faire un update. Ne pas oublier la commande info pour vérifier ces informations.
L’opération effectuée sur chaque objet est donnée par un caractère :
A ajouté
D supprimé
U modifié
C en conflit
G fusionné
status
$ svn st [-u] [fichier|chemin...]Sans arguments affiche les objets locaux modifiés, pas d’accès réseau.
Avec -u, ajoute la révision en cours et précise les objets obsolètes.
Sous Tortoise, l’équivalent de la commande status est l’entrée "check for modifications" depuis le menu contextuel.
export
On utilisera la commande export pour créer une archive par exemple.
$ svn export --force http://domaine.fr/svn/projet/tags/V1.0 <destination>/projet
$ cd <destination>
$ tar zcvf projet-V1.0.tgz projetbranches
Maintenant que nous avons travaillé sur notre branche principale, je désire tester des modifications (importantes) mais sans casser le reste du projet. Nous allons avoir besoin de créer une branche. Nous allons utiliser la commande copy dont la syntaxe est la suivante :
$ pwd
$ projet/trunk
$ svn copy http://domaine.fr/svn/projet/trunk \
http://domaine.fr/svn/projet/branches/nouveau_projet \
-m "création d'une branche, commentaires...."A la différence de CVS, une fois la branche soumise (commit), il faut l’importer dans un répertoire.
$ cd ..
$ pwd
$ projet
$ svn co http://domaine.fr/svn/projet/branches/nouveau_projet branchespropriétés
Avec subversion, certaines variables ne sont pas expansées par défaut, il faut pour cela utiliser le mécanisme des propriétés. Voici la procédure pour activer l’expansion de la variable $Id$ pour un fichier :
$ svn [-R] propset svn:keywords "Id" [fichiers|répertoire...]
$ svn ci -m "défini le propset pour Id" [fichiers|répertoire...]Utiliser également la propriété svn:ignore afin de ne pas inclure certains fichiers ou répertoires dans la gestion du code :
$ svn remove bin/
$ svn propset svn:ignore "*" bin/
$ svn ci -m "ignore le contenu du répertoire bin"
$ svn updatePermettre à certains fichiers d’être exécutables :
$ svn propset svn:executable ON *.plswitch
Actualise la copie de travail avec une nouvelle URL.
$ svn switch --relocate <old_URL <new_URL>
$ svn updateSous Tortoise (Windows), utiliser la commande Relocate depuis le menu contextuel.
Liens utiles
- En français
- Une doc complète sur ToutProgrammer.com
- Wikipedia
- La documentation de Tortoise en Français
- En anglais
- Le site de Subversion
- Collabnet subversion
- Divers
- TortoiseSvn, client GUI sous Windows
- Aide complète en ligne sur Tortoise.
- RapidSvn, client GTK sous Linux